需求
建立一个可以实时查询履行各个应用的各个流程场景的成功数失败数的报表,提供按照时间范围,应用流程场景,行业维度的查询条件,并且提供下钻查看展示相应处理信息的功能。
日志数据
目前履行接入histore的日志有fdc,fcs两个应用。日志量每天1亿,日志诊断功能已经开发完成,所以下钻功能只需提供相应的跳转链接即可。
日志表结构
CREATE TABLE IF NOT EXISTS `ifp_monitor_scene` (
`log_time` datetime NOT NULL COMMENT '日志打印时间',
`log_millisecond` varchar(20) DEFAULT NULL COMMENT '日志打印毫秒',
`out_biz_code` varchar(100) DEFAULT NULL COMMENT 'LP号 filter',
`sub_out_biz_code` varchar(100) DEFAULT NULL COMMENT '运单号 filter',
`sp_code` varchar(100) DEFAULT NULL COMMENT '服务商品code lookup',
`user_id` varchar(100) DEFAULT NULL COMMENT '用户id filter',
`flow_id` varchar(100) DEFAULT NULL COMMENT '流程id filter',
`trace_id` varchar(100) DEFAULT NULL COMMENT '鹰眼id filter',
`rpc_id` varchar(100) DEFAULT NULL COMMENT 'rpc id',
`scene_code` varchar(100) DEFAULT NULL COMMENT '场景code lookup',
`app_name` varchar(20) DEFAULT NULL COMMENT '应用名称 lookup',
`execute_time` varchar(20) DEFAULT NULL COMMENT '执行时间',
`success` varchar(20) DEFAULT NULL COMMENT '是否执行成功 lookup',
`error_code` varchar(100) DEFAULT NULL COMMENT '错误码 lookup',
`error_desc` varchar(1000) DEFAULT NULL COMMENT '错误描述',
`sub_error_code` varchar(100) DEFAULT NULL COMMENT '子错误码 lookup',
`sub_error_desc` varchar(1000) DEFAULT NULL COMMENT '子错误描述',
`feature` varchar(2048) DEFAULT NULL COMMENT '额外feature信息',
`result` longtext COMMENT '执行详细日志',
`host_ip` varchar(40) DEFAULT NULL COMMENT 'host ip',
`retry` varchar(20) DEFAULT NULL COMMENT '是否重试 lookup',
`yace_flag` varchar(20) DEFAULT NULL COMMENT '压测标示 lookup'
) ENGINE=HISTORE DEFAULT CHARSET=utf8 COMMENT='ifp场景执行日志';
设计方案
之前有了解过histore的原理,它可以提供百亿数据下仍然快速查询的性能,并且聚合函数相关操作(count,sum,min,max)都能在常数时间返回,所以一开始是想直接借助histore聚合函数查询快这一特性直接使用sql count语句聚合统计每10s内应用各个流程场景的成功数失败数。
方案1
- 前端页面:之前订单平台也有做过类似的日志实时统计报表,所以前端页面有参考他们使用的统计图,进入订单平台的统计页面,右键查询源代码,他们所使用统计图类型一目了然,是highchart,查看官网文档,除开统计图样式参数外,最核心的就是统计图的数据类型了,highchart统计图数据类型如下,传入多个(x,y)点,即可在统计图上绘制曲线出来。此次使用的x轴坐标为时间,y轴坐标表示(x-10000,x)这个时间段内的日志总数,即10s内的日志总数
[
[
1514764800000,
347
],
[
1514764810000,
352
],
[
1514764820000,
298
],
[
1514764830000,
287
],
[
1514764840000,
272
]
]
前端统计图展示效果
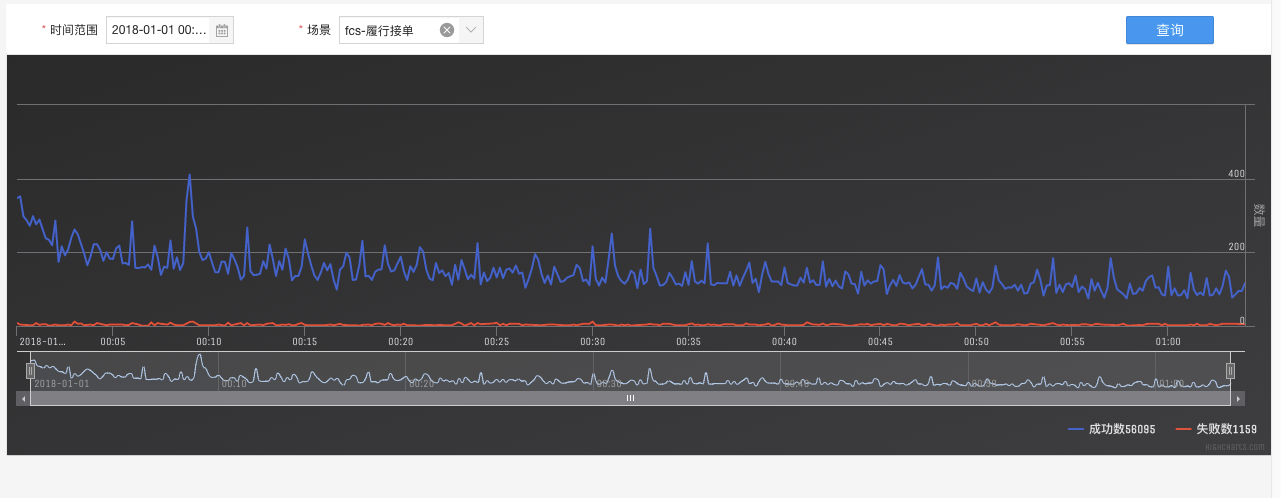
后端设计:后端需要提供给前端每10s内的日志成功与失败的总数,前端查询参数会给出时间范围,所以首先把时间范围切片,分成10s一片,例如查询范围是2017-12-5 08:00:00 到2017-12-5 09:00:00的,按照10s切片后,就分成了 1 60 60/10=360片,每片一个sql count查询,由于查询请求多,所以采用多线程进行查询,然后汇总,线程池参数为 coreSize=30,maxSize = 30,即30个线程并发查询,使用CountDownLacth控制线程。
方案1效果
在日常环境下,可以最多五个小时的时间范围查询,同时支持按照流程场景,错误码,行业等维度查询,但是部署到预发后,由于预发和线上日志是同一数据库的,日志量大,只能查询出15分钟范围内的数据,效果非常不理想,完全无法满足需求。所以有了下面的方案2
方案2
- 前端不涉及到性能问题,所以如上,不进行改动
- 后端:方案1使用的是实时的sql count,每查询一次就聚合一次,但是日志数据都是历史数据,不会再有改变,例如你查询昨天一天内fcs履行接单的数据,不管如何查询,结果都是一样的,不会再有变动,所以我们数据可以提前聚合好,存放在数据库里面,等用户查询时,只要把聚合的数据返回给用户就行。
- 履行的日志是使用tlog中间件采集的,tlog也提供日志聚合的功能,聚合设计如下
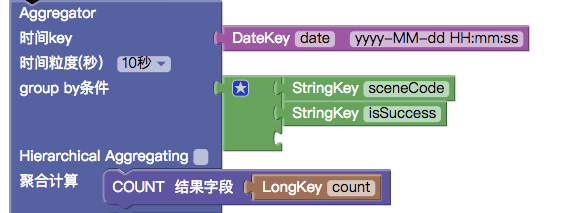
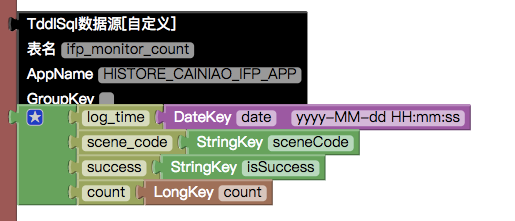
聚合数据结构,目前方案是先支持按照流程场景下的查询,所以按照行业(sp_code),错误码(error_code),流程code(process_code)的查询是先在数据表里面预留字段,日后再支持。
--表ifp_monitor_count --数据链路(四个选填一个):从tlog导入 --建表语句: CREATE TABLE IF NOT EXISTS
ifp_monitor_count(log_timedatetime NOT NULL COMMENT '日志打印时间',scene_codevarchar(100) DEFAULT NULL COMMENT '场景code lookup',successvarchar(20) DEFAULT NULL COMMENT '是否执行成功 lookup',error_codevarchar(100) DEFAULT NULL COMMENT '错误码 lookup',sp_codevarchar(100) DEFAULT NULL COMMENT '服务商品code lookup',process_codevarchar(100) DEFAULT NULL COMMENT '流程code lookup',countbigint(11) DEFAULT 0 COMMENT '日志总数 lookup', ) ENGINE=HISTORE DEFAULT CHARSET=utf8 COMMENT='ifp场景执行日志';
- 后端代码实现逻辑:数据已经聚合存放在数据库,25W/天,由于查询条件中流程场景必选,所以25W/流程场景数,大概每次查询出1-2W的数据,然后返回给前端,之前有过经历,当一次查询时返回结果过多,rt延迟会很高,所以这次还是采用多线程进行查询,将查询的时间范围按照1个小时进行切片,每个线程拉取一小时的数据。
方案2效果
预发环境下,查询一天的日志统计情况,rt=200ms左右,日志统计是从2017-12-26开始的,截止到今天2018-01-01,共7天的数据量都可查询出来,rt=1200ms左右,呈线性增长趋势。目前方案2已经投入线上使用。
后续开发思考
- 目前方案2是只支持按照时间范围和流程场景下的查询,跟丁锐沟通后,后续还要增加行业维度和错误码维度的查询,行业维度共有25个,如果tlog聚合再增加一个行业条件,每天日志聚合量为25W*25=625W/每天,错误码维度由于与流程场景绑定在一起,无法估计其日志增长数量,但可以预测到当行业维度和错误码维度增加后,日志聚合量会达到1000W/每天,如果用户想查看fcs履行接单不分行业的一天的统计情况,至少需要从histore查询出100W的数量,然后聚合返回给前端,以目前的方案,不太能满足需求,需要思考后续方案。