1产品介绍
tair是集团一款分布式的NoSQL存储产品,目前有mdb,rdb,ldb三款产品,mdb与rdb都是内存行产品,其中mdb支持KV和类hashmap结构,性能比rdb好,但不支持持久化存储,rdb采用redis的内存存储结构,支持KV,List,Hash,Set,SortedSet等数据结构,提供缓存和持久化存储两种模式,ldb属于持久化产品,支持KV和类hashmap结构,性能最低,但是持久化可靠性最高。
系统架构
tair集群包括configServer,dataServer,invalidServer和client四个模块
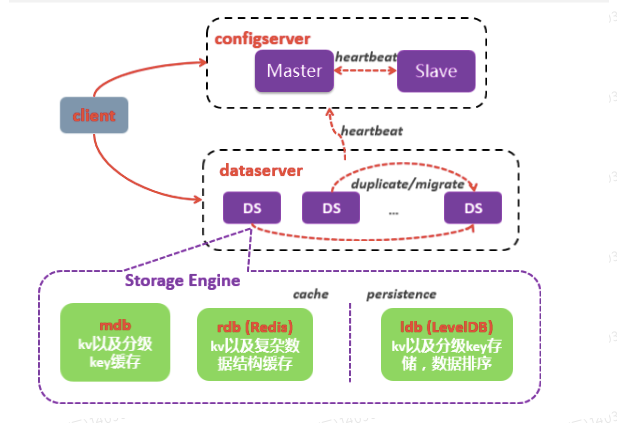
configServer
- 维护dataServer集群信息
- 根据存活节点的信息构建数据在集群中的分布表,并提供分布表查询服务
- 调度dataServer之间的数据迁移,复制
- configServer通常有两台互为主备
dataServer
- 信息实际存储载体
- 接受client端的put/get/remove等操作
- 执行数据迁移和复制
invalidServer
- 接受client端的invalid/hide操作,可以对同一组的集群做delete/hide操作,因为集群容灾方式可能为双机房独立部署方式,数据需要更新时,使用client端的put操作,只能对一个机房的数据进行更新操作,另外一个机房数据仍然是旧版数据,所以需要使用invalid操作来失效集群中的数据,然后把将数据put到当前机房的tair集群,该数据会同步到后端数据源,当另外一个集群查询数据时发生no exist时会去后端数据源读取数据放入tair,从而保证数据的一致性。
client
- 在应用端提供tair集群的接口
- 更新并缓存configServer的分布表和invalidServer的地址
- LocalCache,避免过热数据访问影响tair集群服务
基本概念
configId
一个tair集群的唯一标识id,当前大部分应用该id存放在diamond中,初始化tair需要配置该值
area
类似C++中的namesapce,用来支持不同应用在同一集群中存放相同key的数据,也就是当area不相同,但是key相同时,数据不冲突
quota
对应来area存储区的大小限制,当数据量超过quota时,会将数据进行淘汰(LRU算法),ldb没有quota大小限制,但是ldb自带mdb cache,所以如果设置了ldb中mdb cache的quota,则超过该quota时,也会进行数据淘汰
expireTime
数据过期时间,当超过数据过期时间,数据对应用将不可见,expireTime可以是相对时间(30s),或者绝对时间 2018-01-01 00:00:00,当设置为绝对时间时,其实也是在客户端计算出相对时间再传给tair的,当get数据时,tair会检验该数据的expireTime,如果过期则返回给用户数据不存在的结果,同时清除掉该数据。如果传入的expireTime小于0 ,有两种情况,第一种是数据新增的情况,则表示数据永不过期,第二种是数据更新的情况,则沿用之前数据的expireTime,不进行覆盖操作。当不传入exipreTime时,表示数据永不过期,当传入的expireTime大于0且小于当前时间戳,则认为该expireTime相对时间,当expireTIme大于当前时间戳,则认为是绝对时间。
version
数据的版本号,也就是乐观锁的版本号,用于并发控制,get操作的数据有带有版本号,在使用put操作更新数据时,加上版本号就行,如果不考虑版本问题,可以把版本号设置为零,将强行覆盖数据。如果put新数据没有设置版本号,则默认版本号为1。
分布式策略
tair的分布式采用一致性hash算法,对于所有的key,分布到N个桶中,configSerever根据一定策略将桶指派给不同的dataServer,configServer的分布表记录的就是桶与dataServer的对应关系,数据的key进行hash会得到一个桶编号,然后再去configServer查询桶编号对应的dataServer,再到指定的dataServer查询数据。
集群部署方式
双机房单集群单份
tair集群分布在两个机房中,但是数据只存储一份
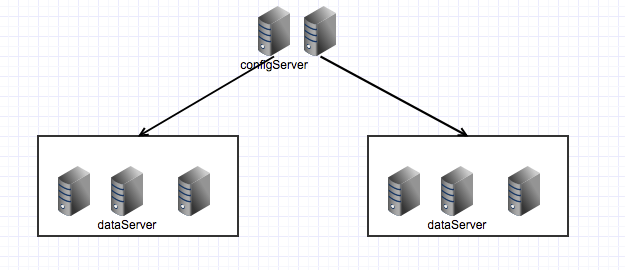
- 优点:任意一个机房宕机仍然保持可用
- 缺点:数据只保持一份,不同机房存储不同的数据,所以应用会跨机房访问,当一个机房出现故障,则该机房的数据会失效。
双机房独立集群
在两个机房同时部署两个独立的集群,两机房的集群没有直接联系,可以理解为两个机房的数据互为备份,client的操作只能作用于一个机房,所以需要使用invalidServer来操作两个机房的集群。由于两个集群相互独立,不会做数据同步操作,所以集群必须配置后端数据源来保持两个集群的数据一致性。
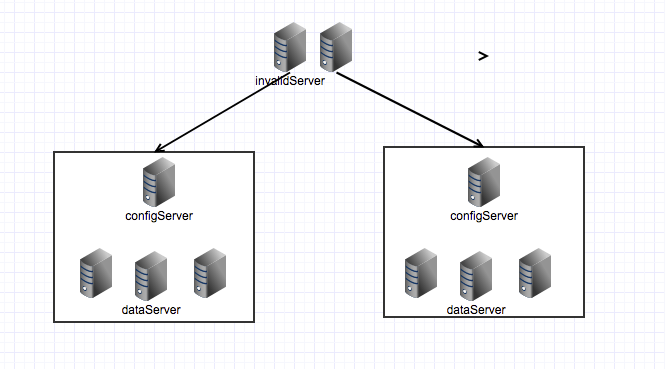
- 优点:每个机房拥有独立的集群,具有全部的数据,所以应用在那个机房就访问哪个机房的集群,不会跨机房访问,当一个机房出现故障,不会影响业务访问tair命中率
- 缺点:集群之间不会做数据备份,所以需要配置后端数据源,当后端数据源发生更新时,需要先调用invalid操作让所有集群数据失效,然后才能进行put操作进行数据更新(put操作只会更新一个机房的集群数据,当访问到另外一个机房时,由于之前的invalid操作,数据已经失效,所有会发生no exist,这时会后端数据源拉取数据放到该机房)
双机房单集群双份
将集群部署到两个机房中,数据保存芳芬,并且同一数据的两个备份不会放在同一数据服务器上,根据数据分布策略的不同,还可以将同一份数据的不同备份分布到不同的机房。该部署方式的存储引擎是mdb
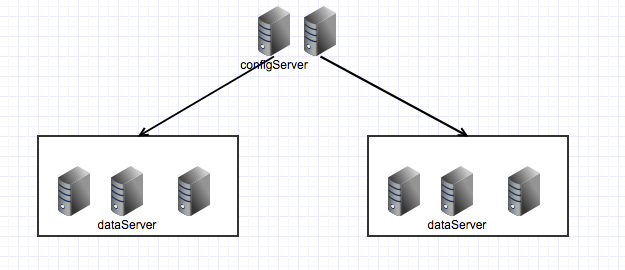
- 优点:后端无需数据源,一个机房故障了,另外一个机房仍然可以服务,且数据不丢失
- 缺点:由于存储引擎是mdb,且没有后端持久化的数据源,如果机房全部发生故障,仍然会造成数据丢失,如果两个机房之间网络出现异常,会影响数据的备份,有小概率丢失数据。
双机房主备集群
该部署方式,存在一个主集群和备集群,分别在两个机房,正常情况下,用户的读写操作只与主集群交互,当主集群机房发生故障,备集群会自动切换成主集群,提供服务。主备集群会自动同步数据。该部署方式的存储引擎是ldb